Read more: Technical report, Code, Hugging Face weights
Introduction
One of the core research directions at Radical Numerics is model conversion — the idea that we can optimize models at the level of architecture and training objectives without rebuilding entire systems from scratch. Through model conversion, it becomes possible to iterate faster on models and adapt them to specific workflows, hardware, and downstream tasks.
Diffusion Language Models (DLMs) have long been compelling for researchers because they support parallel generation, unlike autoregressive (AR) models, which are constrained to sequential left-to-right generation. Despite their promise, training DLMs remains challenging due to their relative scaling inefficiency compared to AR models. For instance, direct DLM training requires more passes over a finite dataset to surpass direct AR training [1]. Moreover, AR models benefit from significant incumbency advantages — including mature training infrastructure, stable recipes, and extensive practitioner expertise.
Today, we present our work on scaling diffusion language models by customizing autoregressive models.
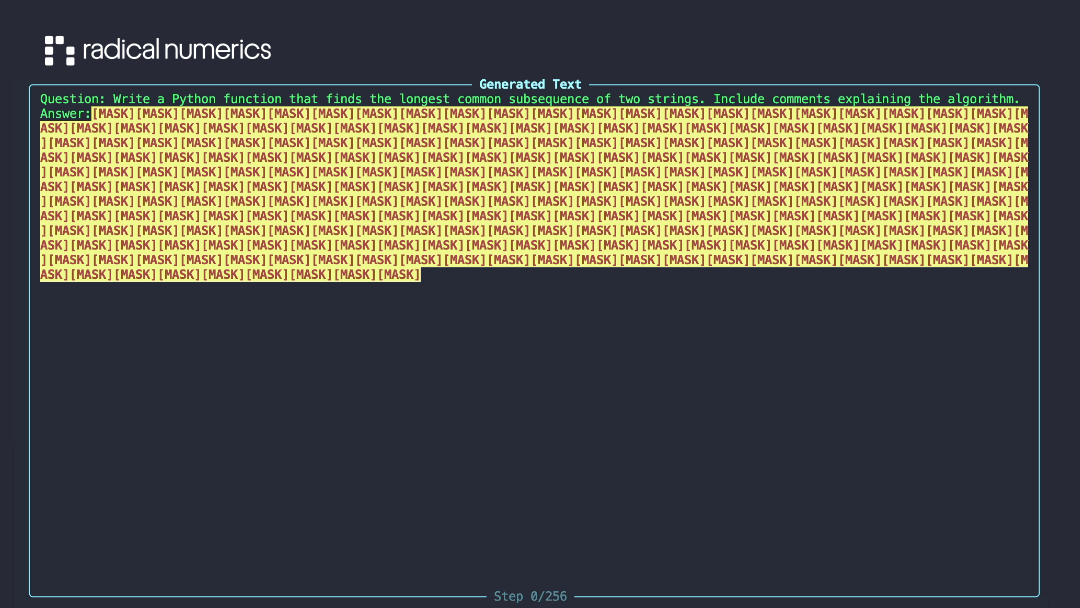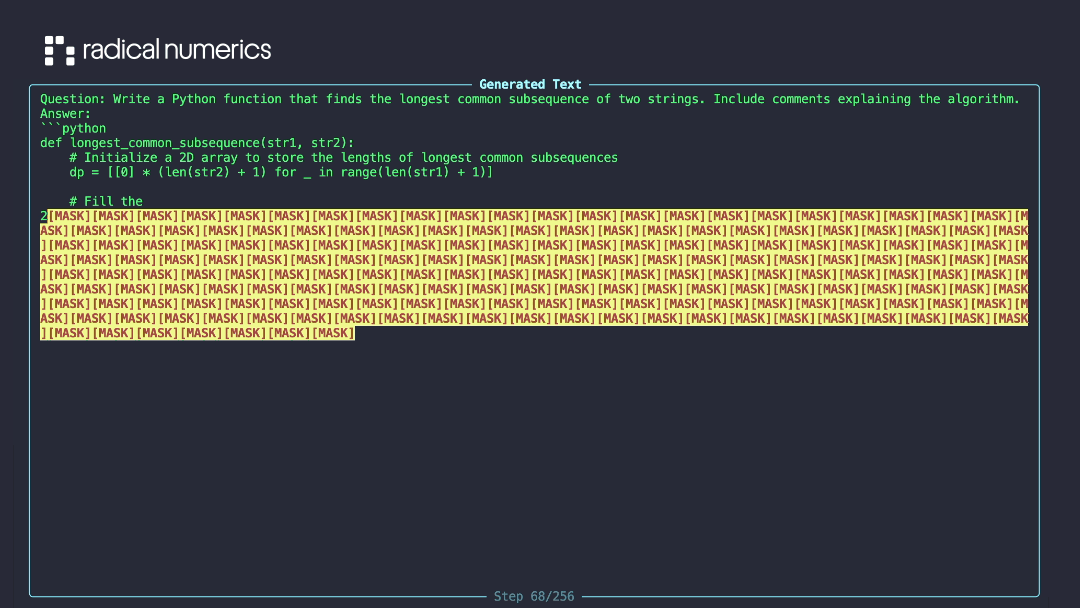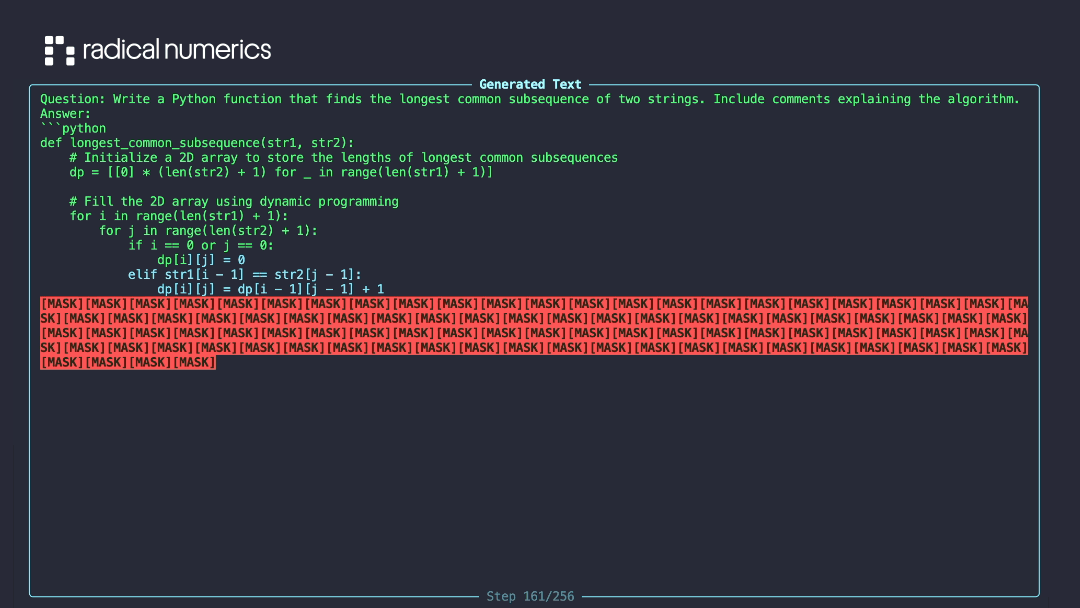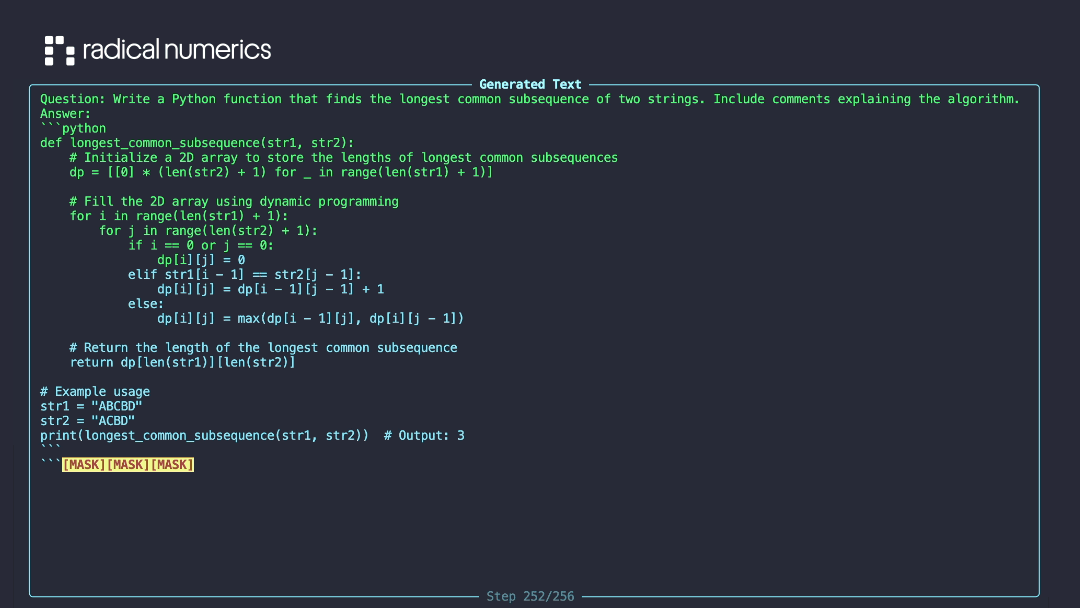
We introduce RND1-Base (Radical Numerics Diffusion), the largest and most capable open-source DLM to date. RND1 is an experimental 30B-parameter sparse Mixture-of-Experts model with 3B active parameters, converted from a pretrained AR model (Qwen3-30BA3B) and continually pretrained for 500B tokens to achieve full diffusion behavior. We release the model alongside our training recipe, inference code, and sample outputs.
Our contributions include:
-
We systematically study A2D conversion at scale, e.g. initialization, layer-specific learning rates, and critical batch size.
-
We identify factors that enable scaling and stability, showing that when coupled with established autoregressive pretraining methodologies, the combination of simple techniques can yield scalable DLMs.
-
We introduce RND1-30B, the largest and most capable base DLM to date, demonstrating that principled conversion of AR pretraining science can produce high performance across a variety of benchmarks.
Simple Continual Pretraining (SCP)
Training a diffusion language model from an autoregressive (AR) checkpoint raises two central questions. First, how can we introduce bidirectional context into a model whose architecture was trained under strictly causal attention? Second, how can we preserve the vast linguistic and factual knowledge that the AR model already encodes from trillions of tokens of pretraining?
Earlier work proposed complex multi-stage pipelines, such as attention mask annealing [4,5], which gradually relaxes the causal mask to enable bidirectionality, or grafting [6], which systematically edits model architectures to swap causal attention with bidirectional attention.
While effective at small scale, these methods tend to introduce additional design choices (e.g., mask transition policies, annealing/grafting schedule) making them difficult to scale reliably.
In contrast, we find that a far simpler approach, Simple Continual Pretraining (SCP), matches the performance of more sophisticated A2D conversion recipes. The recipe is straightforward:
- Start from a strong AR checkpoint.
- Replace the causal mask with a bidirectional mask at initialization.
- Continue pretraining under the masked diffusion objective with learning rate warmup.
Retaining AR pretraining knowledge via layer-specific learning rates
A key concern in A2D conversion is catastrophic forgetting: A2D conversion may overwrite factual knowledge learnt during AR pretraining. Prior studies demonstrate that knowledge (especially factual associations) in Transformer-based LMs are encoded in the FFN/MLP layers [2,3].
Building on this insight, we adopt variable learning-rate across parameter groups. During conversion, attention layers receive higher learning rates to promote adaptation to bidirectional context, while non-attention layers (e.g., MLPs, embeddings) are trained with lower learning rates to retain AR pretraining knowledge.
A2D conversion thrives with larger batch sizes
One subtle but important difference between autoregressive and diffusion training lies in how much supervision each batch provides. In autoregressive (AR) models, every token contributes to the loss. In contrast, masked diffusion objectives supervise only the masked positions within each sequence. Under the standard masked diffusion objective, the average masking ratio is 50%, therefore only half the tokens in a batch influence learning. This reduced learning signal means that standard AR heuristics for scaling batch size and learning rate don’t necessarily transfer to diffusion training.
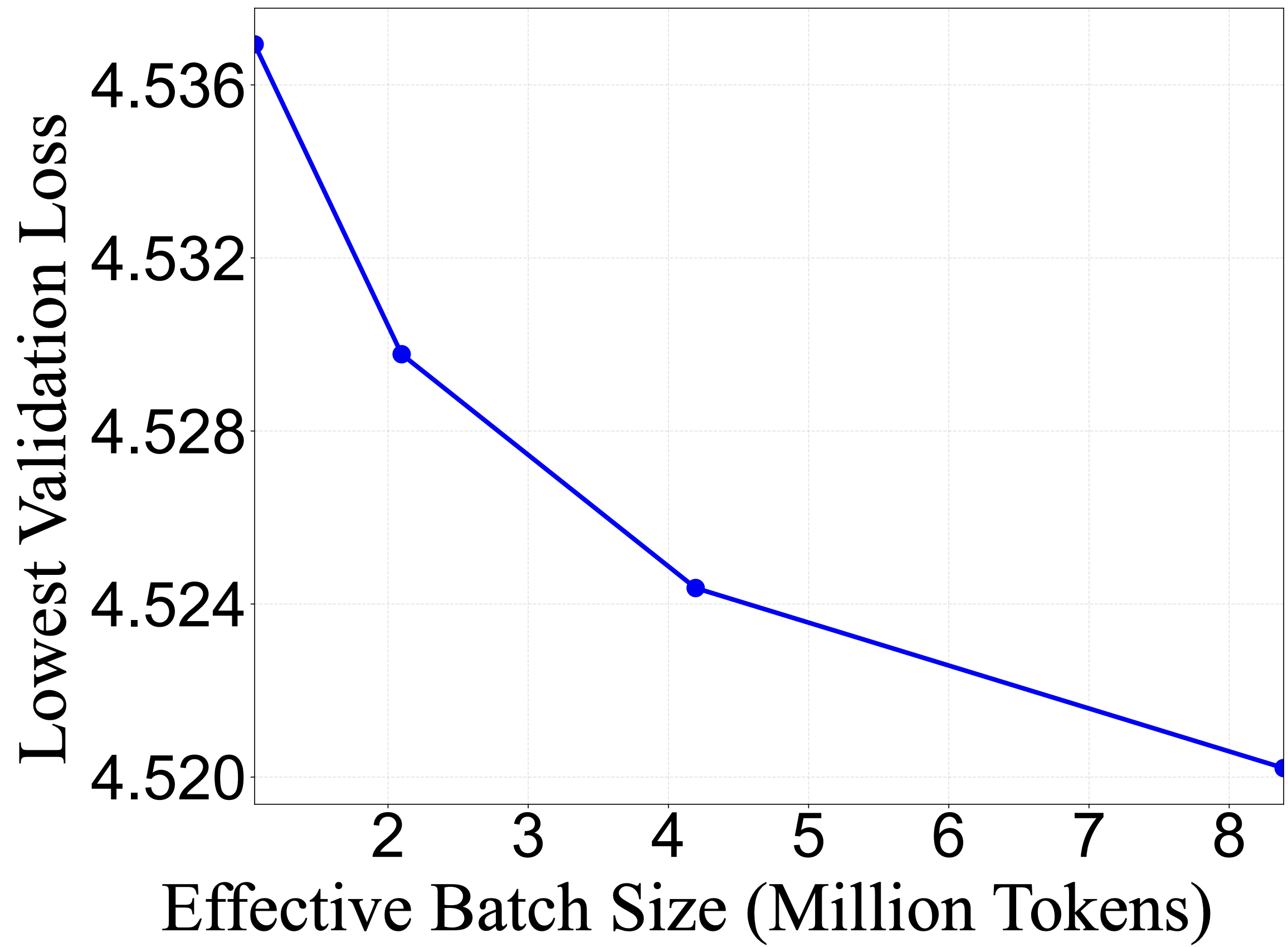
To better understand this, we estimate the critical batch size (CBS)—the threshold beyond which increasing data parallelism yields diminishing returns in loss improvement. Following the approach of [7,8], we use branched training to empirically locate this point.
Starting from a 4B parameter model checkpoint trained for 60B tokens under our Simple Continual Pretraining (SCP) recipe, we launch four parallel training runs that differ only in their effective global batch size. We scale the learning rate while keeping optimizer settings and weight decay fixed, and align warmup and decay schedules in token space across runs. Each branch trains for an additional 5B tokens.
Our results show that the final diffusion loss for each branched run continues to decrease monotonically up to 8M tokens at the 4B model scale. In other words, diffusion language models benefit from large batch sizes during continual pretraining, an encouraging signal for large-scale training.
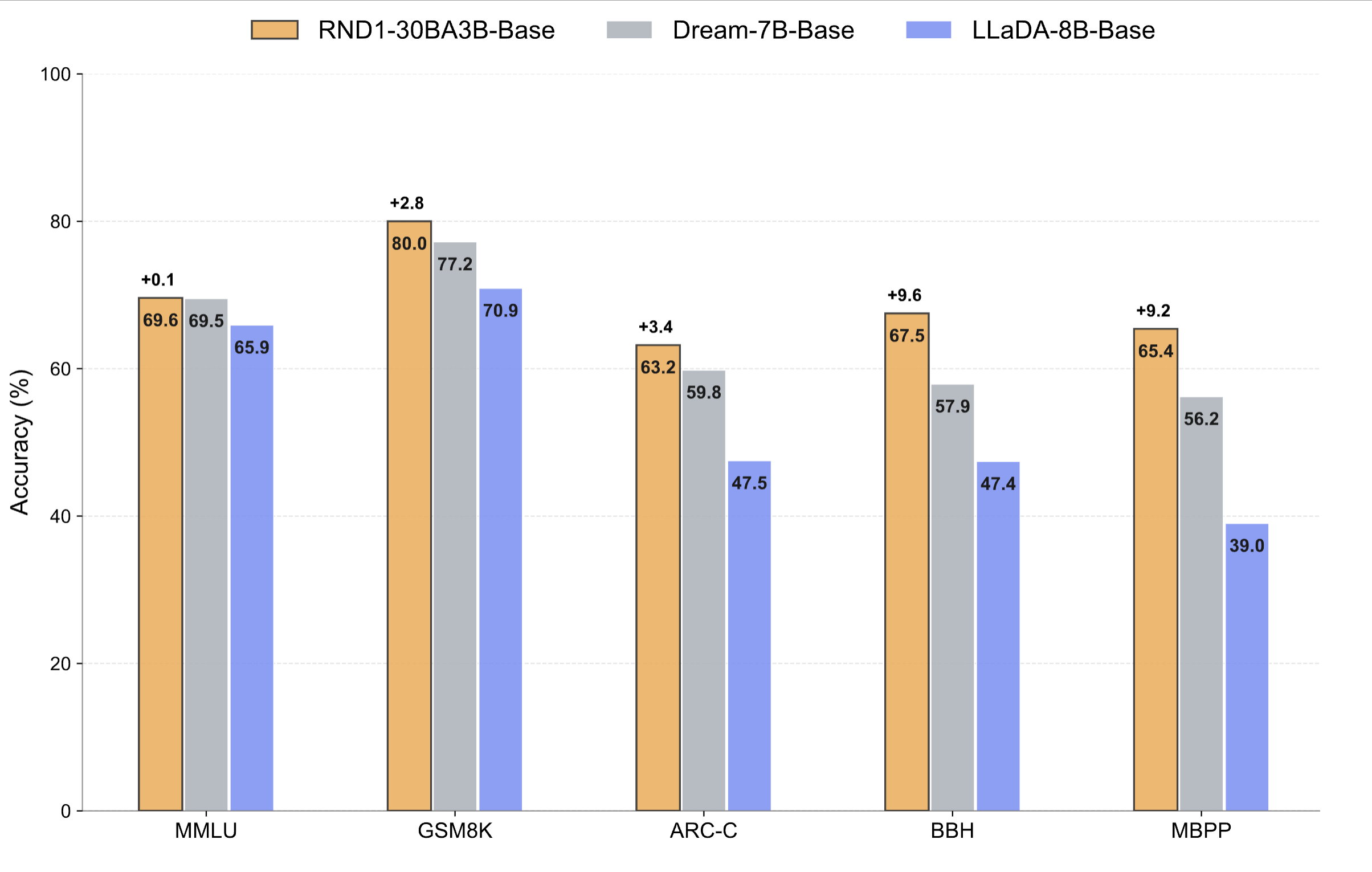
RND1 evaluation
On general-purpose benchmarks spanning reasoning, STEM, and coding, RND1 sets a new state of the art among open diffusion language models (DLMs). RND1 consistently outperforms prior open diffusion baselines (Dream-7B and LLaDA-8B), while preserving the strong performance of its autoregressive (AR) foundation. We test RND1 on reasoning & commonsense (MMLU, ARC-C, RACE, BBH), STEM & math (GSM8K), and code generation (MBPP) tasks.
These results collectively indicate that scaling diffusion language models beyond 8B parameters is not only feasible but practical, and A2D may be a better strategy to train DLMs. RND1 represents the first open-source effort to demonstrate diffusion model training at this scale.
Why model customization?
RND1 shows how new architectures and training paradigms can be explored efficiently at scale without starting from scratch. These techniques allow us to experiment with far more scaling recipes in our mission to build general biological intelligence.
Citation
@article{rnd1_2025,
title = {RND1: Simple, Scalable AR-to-Diffusion Conversion},
author = {Chandrasegaran, Keshigeyan and Thomas, Armin W. and Ku, Jerome and Berto, Federico and Kim, Jae Myung and Brixi, Garyk and Nguyen, Eric and Massaroli, Stefano and Poli, Michael},
year = {2025},
month = {Oct},
url = {https://www.radicalnumerics.ai/blog/rnd1},
organization = {Radical Numerics}
}
References
[1] Prabhudesai, Mihir, et al. "Diffusion beats autoregressive in data-constrained settings." arXiv preprint arXiv:2507.15857(2025).
[2] Meng, Kevin, et al. "Locating and editing factual associations in gpt." Advances in neural information processing systems 35 (2022): 17359-17372.
[3] Dai, Damai, et al. "Knowledge Neurons in Pretrained Transformers." Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022.
[4] Gong, Shansan, et al. "Scaling Diffusion Language Models via Adaptation from Autoregressive Models." The Thirteenth International Conference on Learning Representations.
[5] Ye, Jiacheng, et al. "Dream 7b: Diffusion large language models." arXiv preprint arXiv:2508.15487 (2025).
[6] Chandrasegaran, Keshigeyan, et al. "Exploring Diffusion Transformer Designs via Grafting." Advances in Neural Information Processing Systems 38 (2025)
[7] McCandlish, Sam, et al. "An empirical model of large-batch training." arXiv preprint arXiv:1812.06162 (2018).
[8] Merrill, William, et al. "Critical Batch Size Revisited: A Simple Empirical Approach to Large-Batch Language Model Training." arXiv preprint arXiv:2505.23971 (2025).
Team
Keshigeyan Chandrasegaran, Armin W. Thomas, Jerome Ku, Jae Myung Kim, Federico Berto, Garyk Brixi, Eric Nguyen, Stefano Massaroli, Michael Poli